
Changfeng Ma
PhD Student
马常风
Changfeng Ma
Nanjing University
PhD Student, NJU Meta Graphics & 3D Vision Lab, Computer Science and Technology, Nanjing University, Nanjing, China, 210023.
Supervisor: Prof. Yanwen Guo
ORCID: 0000-0001-8732-7038
BIOGRAPHY
I received my bachelor's degree (2021) from the department of Computer Science and Technology (Honored Class) at Nanjing University. I am currently working toward the PhD degree in the department of Computer Science and Technology at Nanjing University. My research interests include 3D computer vision and point cloud understanding.
Research Interests
- 3D Computer Vision
- 3D Generation
- 3D Object and Scene Reconstruction and Analysis
- Point Cloud Processing and Learning
Education
- 2017-2021, B.Sc., Computer Science and Technology (Honored Class), Nanjing University
- 2021-, Ph.D., Computer Science and Technology, Nanjing University
Internship
- 2025.5.22-, Tencent Hunyuan 3D, Shanghai, China, Research Intern (QingYun Top Project)
PUBLICATION
-
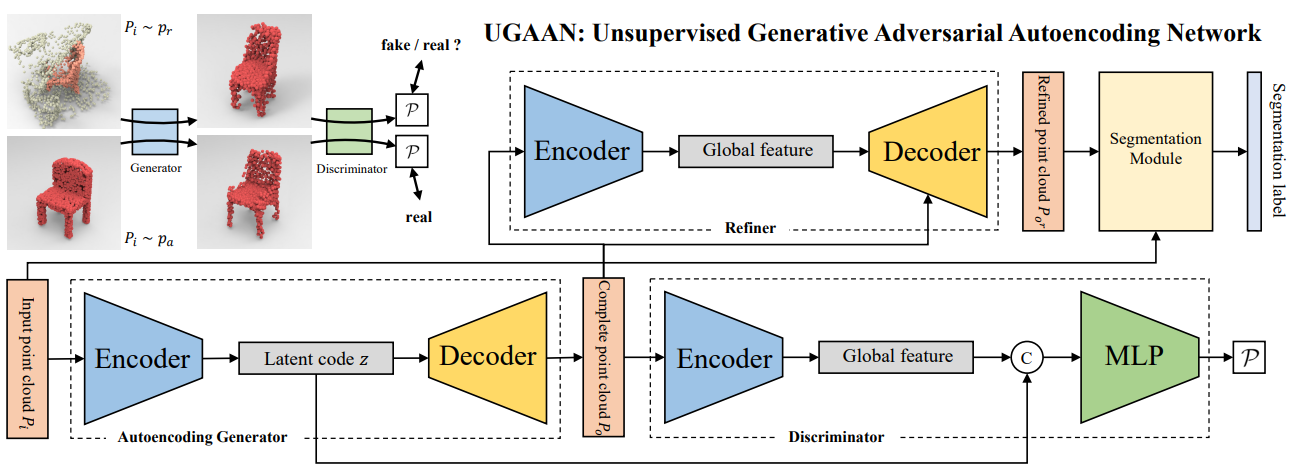
(NIPS2022) Chanfeng Ma, Yang Yang, Jie Guo, Fei Pan, Chongjun Wang, Yanwen Guo. Unsupervised Point Cloud Completion and Segmentation by Generative Adversarial Autoencoding Network. [paper][code] More
ABSTRACT: Most existing point cloud completion methods assume the input partial point cloud is clean, which is not practical in practice, and are Most existing point cloud completion methods assume the input partial point cloud is clean, which is not the case in practice, and are generally based on supervised learning. In this paper, we present an unsupervised generative adversarial autoencoding network, named UGAAN, which completes the partial point cloud contaminated by surroundings from real scenes and cutouts the object simultaneously, only using artificial CAD models as assistance. The generator of UGAAN learns to predict the complete point clouds on real data from both the discriminator and the autoencoding process of artificial data. The latent codes from generator are also fed to discriminator which makes encoder only extract object features rather than noises. We also devise a refiner for generating better complete cloud with a segmentation module to separate the object from background. We train our UGAAN with one real scene dataset and evaluate it with the other two. Extensive experiments and visualization demonstrate our superiority, generalization and robustness. Comparisons against the previous method show that our method achieves the state-of-the-art performance on unsupervised point cloud completion and segmentation on real data.
TL;DR: We propose an unsupervised method for point cloud completion and segmentation.
-
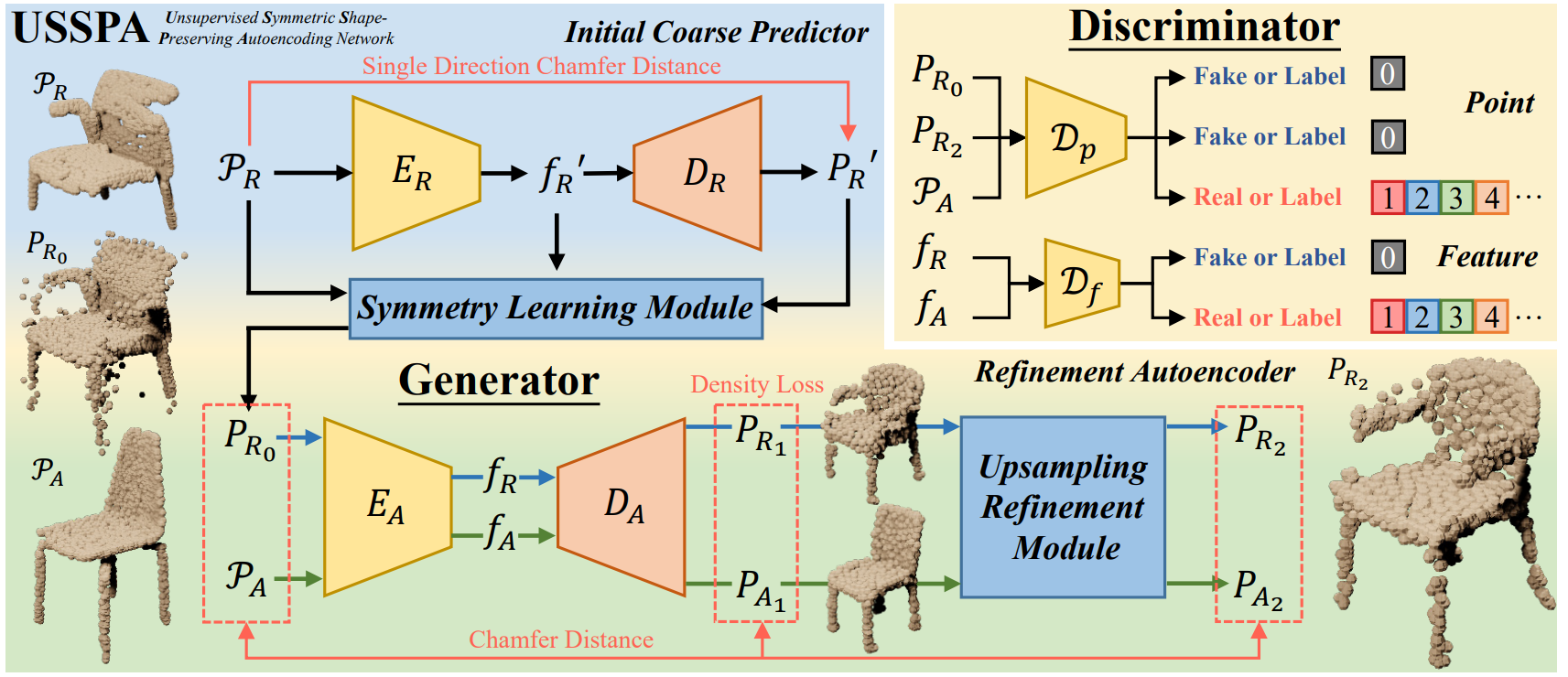
(CVPR2023) Chanfeng Ma, Yinuo Chen, Pengxiao Guo, Jie Guo, Chongjun Wang, Yanwen Guo. Symmetric Shape-Preserving Autoencoder for Unsupervised Real Scene Point Cloud Completion. [paper][code] More
ABSTRACT: Unsupervised completion of real scene objects is of vital importance but still remains extremely challenging in preserving input shapes, predicting accurate results, and adapting to multi-category data. To solve these problems, we propose in this paper an Unsupervised Symmetric Shape-Preserving Autoencoding Network, termed USSPA, to predict complete point clouds of objects from real scenes. One of our main observations is that many natural and man-made objects exhibit significant symmetries. To accommodate this, we devise a symmetry learning module to learn from those objects and to preserve structural symmetries. Starting from an initial coarse predictor, our autoencoder refines the complete shape with a carefully designed upsampling refinement module. Besides the discriminative process on the latent space, the discriminators of our USSPA also take predicted point clouds as direct guidance, enabling more detailed shape prediction. Clearly different from previous methods which train each category separately, our USSPA can be adapted to the training of multi-category data in one pass through a classifier-guided discriminator, with consistent performance on single category. For more accurate evaluation, we contribute to the community a real scene dataset with paired CAD models as ground truth. Extensive experiments and comparisons demonstrate our superiority and generalization and show that our method achieves state-of-the-art performance on unsupervised completion of real scene objects.
TL;DR: We propose an unsupervised method and an evaluation method for unsupervised (unpaired) real scene point cloud completion and achieve SOTA performance.
-
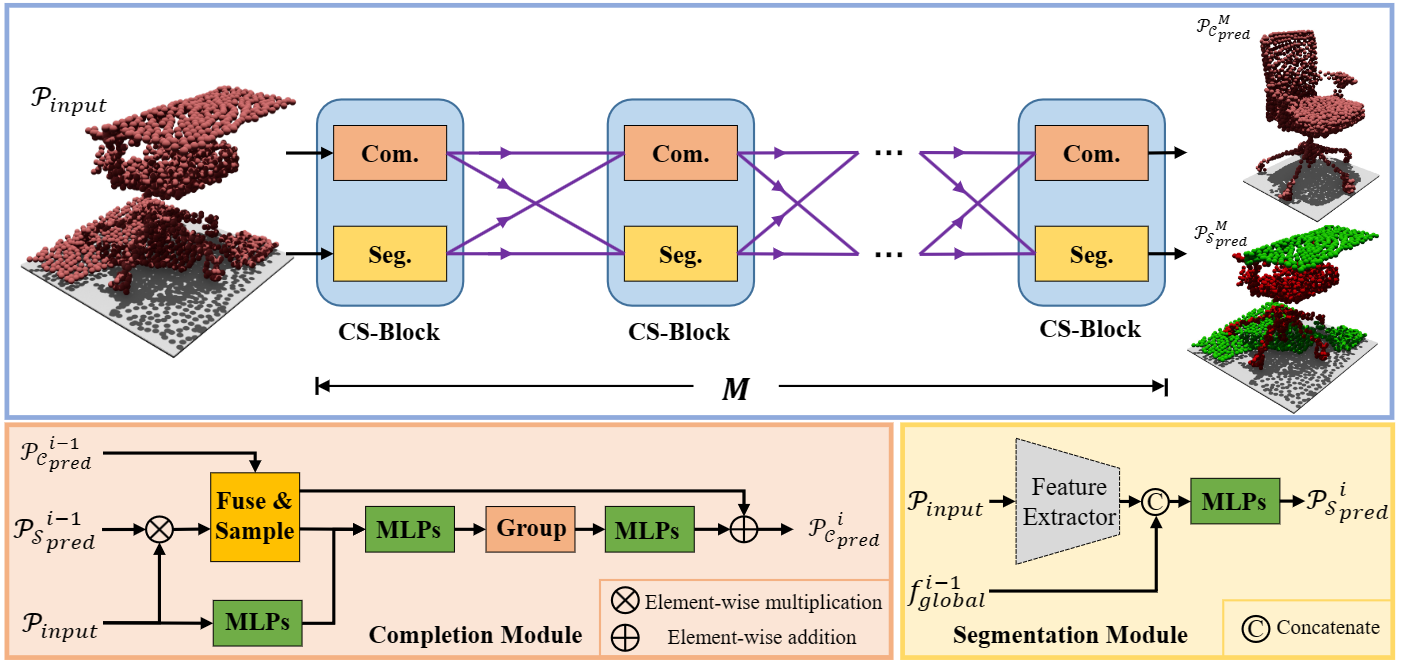
(TVCG accpeted 2023-10-18) Chanfeng Ma, Yang Yang, Jie Guo, Mingqiang Wei, Chongjun Wang, Yanwen Guo, Wenping Wang. Collaborative Completion and Segmentation for Partial Point Clouds with Outliers. [paper] [code (coming soon) (email me if you need)] More
ABSTRACT: Outliers will inevitably creep into the captured point cloud during 3D scanning, degrading cutting-edge models on various geometric tasks heavily. This paper looks at an intriguing question that whether point cloud completion and segmentation can promote each other to defeat outliers. To answer it, we propose a collaborative completion and segmentation network, termed CS-Net, for partial point clouds with outliers. Unlike most of existing methods, CS-Net does not need any clean (or say outlier-free) point cloud as input or any outlier removal operation. CS-Net is a new learning paradigm that makes completion and segmentation networks work collaboratively. With a cascaded architecture, our method refines the prediction progressively. Specifically, after the segmentation network, a cleaner point cloud is fed into the completion network. We design a novel completion network which harnesses the labels obtained by segmentation together with farthest point sampling to purify the point cloud and leverages KNN-grouping for better generation. Benefited from segmentation, the completion module can utilize the filtered point cloud which is cleaner for completion. Meanwhile, the segmentation module is able to distinguish outliers from target objects more accurately with the help of the clean and complete shape inferred by completion. Besides the designed collaborative mechanism of CS-Net, we establish a benchmark dataset of partial point clouds with outliers. Extensive experiments show clear improvements of our CS-Net over its competitors, in terms of outlier robustness and completion accuracy.
TL;DR: We propose a Collaborative Completion and Segmentation network for point clouds with noises to predict more accurate completion results.
-
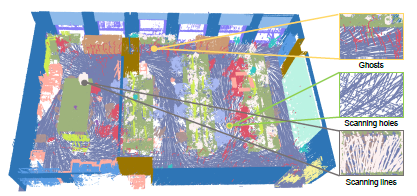
(CVPR2024) Yanwen Guo, Yuanqi Li, Dayong Ren, Xiaohong Zhang, Jiawei Li, Liang Pu, Changfeng Ma, Xiaoyu Zhan, Jie Guo, Mingqiang Wei, Yan Zhang, Piaopiao Yu, Shuangyu Yang, Donghao Ji, Huisheng Ye, Hao Sun, Yansong Liu, Yinuo Chen, Jiaqi Zhu, Hongyu Liu. LiDAR-Net: A Real-scanned 3D Point Cloud Dataset for Indoor Scenes. [paper] [project] More
ABSTRACT: In this paper we present LiDAR-Net a new real-scanned indoor point cloud dataset containing nearly 3.6 billion precisely point-level annotated points covering an expansive area of 30000m^2. It encompasses three prevalent daily environments including learning scenes working scenes and living scenes. LiDAR-Net is characterized by its non-uniform point distribution e.g. scanning holes and scanning lines. Additionally it meticulously records and annotates scanning anomalies including reflection noise and ghost. These anomalies stem from specular reflections on glass or metal as well as distortions due to moving persons. LiDAR-Net's realistic representation of non-uniform distribution and anomalies significantly enhances the training of deep learning models leading to improved generalization in practical applications. We thoroughly evaluate the performance of state-of-the-art algorithms on LiDAR-Net and provide a detailed analysis of the results. Crucially our research identifies several fundamental challenges in understanding indoor point clouds contributing essential insights to future explorations in this field. Our dataset can be found online: http://lidar-net.njumeta.com
TL;DR: We present a new large-scale real-scanned indoor point cloud dataset with LiDAR point cloud scanner, containing different data distribution and more challenging tasks.
-
(CVPR2025) Changfeng Ma, Ran Bi, Jie Guo, Chongjun Wang, Yanwen Guo. Sparse Point Cloud Patches Rendering via Splitting 2D Gaussians. [paper] [code] More
ABSTRACT: Current learning-based methods predict NeRF or 3D Gaussians from point clouds to achieve photo-realistic rendering but still depend on categorical priors, dense point clouds, or additional refinements. Hence, we introduce a novel point cloud rendering method by predicting 2D Gaussians from point clouds. Our method incorporates two identical modules with an entire-patch architecture enabling the network to be generalized to multiple datasets. The module normalizes and initializes the Gaussians utilizing the point cloud information including normals, colors and distances. Then, splitting decoders are employed to refine the initial Gaussians by duplicating them and predicting more accurate results, making our methodology effectively accommodate sparse point clouds as well. Once trained, our approach exhibits direct generalization to point clouds across different categories. The predicted Gaussians are employed directly for rendering without additional refinement on the rendered images, retaining the benefits of 2D Gaussians. We conduct extensive experiments on various datasets, and the results demonstrate the superiority and generalization of our method, which achieves SOTA performance.
TL;DR: We propose a novel point cloud rendering method by predicting 2D Gaussians from point clouds.
-
(TVCG accpeted 2025-6-27) Changfeng Ma, Pengxiao Guo, Shuangyu Yang, Yinuo Chen, Jie Guo, Chongjun Wang, Yanwen Guo, Wenping Wang. Parameterize Structure With Differentiable Template for 3D Shape Generation. [paper] [code (coming soon) (email me if you need)] More
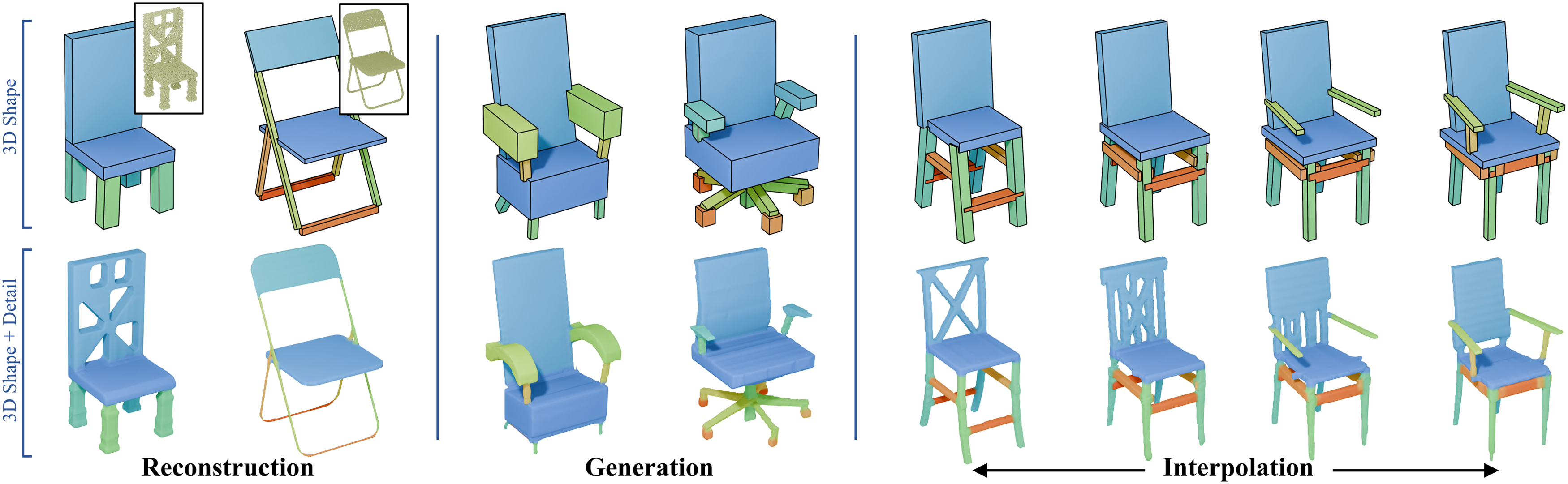
ABSTRACT: Structural representation is crucial for reconstructing and generating editable 3D shapes with part semantics. Recent 3D shape generation works employ complicated networks and structure definitions relying on hierarchical annotations and pay less attention to the details inside parts. In this paper, we propose the method that parameterizes the shared structure in the same category using a differentiable template and corresponding fixed-length parameters. Specific parameters are fed into the template to calculate cuboids that indicate a concrete shape. We utilize the boundaries of three-view renderings of each cuboid to further describe the inside details. Shapes are represented with the parameters and three-view details inside cuboids, from which the SDF can be calculated to recover the object. Benefiting from our fixed-length parameters and three-view details, our networks for reconstruction and generation are simple and effective to learn the latent space. Our method can reconstruct or generate diverse shapes with complicated details, and interpolate them smoothly. Extensive evaluations demonstrate the superiority of our method on reconstruction from point cloud, generation, and interpolation.
TL;DR: We propose a novel method that parameterizes the shared structure in the same category using a differentiable template achieving reconstruction, generation and editing.
-
(Arxiv) Changfeng Ma, Yang Li, Xinhao Yan, Jiachen Xu, Chunshi Wang, Zibo Zhao, Yanwen Guo, Zhuo Chen, Chunchao Guo. P3-SAM: Native 3D Part Segmentation. [paper] [code] [Project] More
ABSTRACT: Segmenting 3D assets into their constituent parts is crucial for enhancing 3D understanding, facilitating model reuse, and supporting various applications such as part generation. However, current methods face limitations such as poor robustness when dealing with complex objects and cannot fully automate the process. In this paper, we propose a native 3D point-promptable part segmentation model termed P3-SAM, designed to fully automate the segmentation of any 3D objects into components. Inspired by SAM, P3-SAM consists of a feature extractor, multiple segmentation heads, and an IoU predictor, enabling interactive segmentation for users. We also propose an algorithm to automatically select and merge masks predicted by our model for part instance segmentation. Our model is trained on a newly built dataset containing nearly 3.7 million models with reasonable segmentation labels. Comparisons show that our method achieves precise segmentation results and strong robustness on any complex objects, attaining state-of-the-art performance. Our code will be released soon.
TL;DR: Segment any 3D objects. SAM for 3D objects.
-
(Arxiv) Xinhao Yan*, Jiachen Xu*, Yang Li, Changfeng Ma, Yunhan Yang, Chunshi Wang, Zibo Zhao, Zeqiang Lai, Yunfei Zhao, Zhuo Chen, Chunchao Guo. X-Part: high fidelity and structure coherent shape decomposition. [paper] [code] [Project] More
ABSTRACT: Generating 3D shapes at part level is pivotal for downstream applications such as mesh retopology, UV mapping, and 3D printing. However, existing part-based generation methods often lack sufficient controllability and suffer from poor semantically meaningful decomposition. To this end, we introduce X-Part, a controllable generative model designed to decompose a holistic 3D object into semantically meaningful and structurally coherent parts with high geometric fidelity. X-Part exploits the bounding box as prompts for the part generation and injects point-wise semantic features for meaningful decomposition. Furthermore, we design an editable pipeline for interactive part generation. Extensive experimental results show that X-Part achieves state-of-the-art performance in part-level shape generation. This work establishes a new paradigm for creating production-ready, editable, and structurally sound 3D assets. Codes will be released for public research.
TL;DR: SOTA Part Generation.



CONTACT
Name: Changfeng Ma
E-mail: changfengma@smail.nju.edu.cn, njumcf@126.com
Github: murcherful
If you can't get access to the pdf, please email me.